


On the inevitability of model collapse
Can AI continue to improve when the internet dies?

The internet is filling up with AI-generated content. No, it’s worse than that. 57% of new content on the web is AI generated one AWS research team found1 and at least one person estimated that will be as high as 90% by the end of the year.2 This is somewhat like the situation you find yourself in at family gatherings when the lid on the ranch dressing comes off and your annoying uncle asks if “you want salad with that dressing” to the chuckle of everyone nearby. Yes, Bob, I’d love a little more internet with my AI!
But here’s the problem: when AI models are trained on data that’s already been generated by other AIs, the quality starts to degrade. The nuance, originality, and weirdness that come from real human thought begin to fade, replaced by the statistical average of whatever was generated before. Over time, this self-referential loop can cause model collapse—a kind of slow-motion decay where models become less accurate, less creative, and, frankly, kind of dumb.

This issue is important to talk about because it threatens the long-term reliability and usefulness of AI systems by attacking it’s source—the data. As the quality of the underlying foundation we rely on degrade, the entire AI ecosystem is at risk of collapse. If most future data comes from other AI models instead of diverse human sources, models will become increasingly homogenized, biased, and detached from real-world nuance.
This is kind of a big deal, and as such I see a lot of my peers talking about it.
The Myth
The problem I have with all of this is that that is where most people stop the conversation and most leaders in this space (who should know better) act as if model collapse is a foregone conclusion. It’s not. It's a risk, sure—but it’s always been a risk to future improvements, and hasn’t stopped us yet. In fact, we have plenty of examples where models train on other models' outputs and actually get better. Wild, I know.
Take model distillation for example. This is the process where a large, powerful model teaches a smaller, more efficient model how to think. Instead of learning directly from raw data, the distilled model learns by mimicking the outputs of the teacher model—kind of like a student copying the answers of the smartest kid in class, but in this case, it actually works out great.
The strangest aspect of this process is that the distilled model will perform better than if they had been trained on the original dataset alone. It’s curious indeed that we can get better smaller models from training them on large models. Doesn’t this fly in the face of everything you’ve been taught about model degeneration? Yes, yes it does.
Human data sucks
See the problem is, human data sucks. It’s garbage. If you don’t believe me, just go read a random teenager’s text message history. A large part of the job of a data scientist for the past decade, at least one worth their salt, has been to clean up data. And it’s not just because the data is accidentally bad, it’s often intentionally bad.
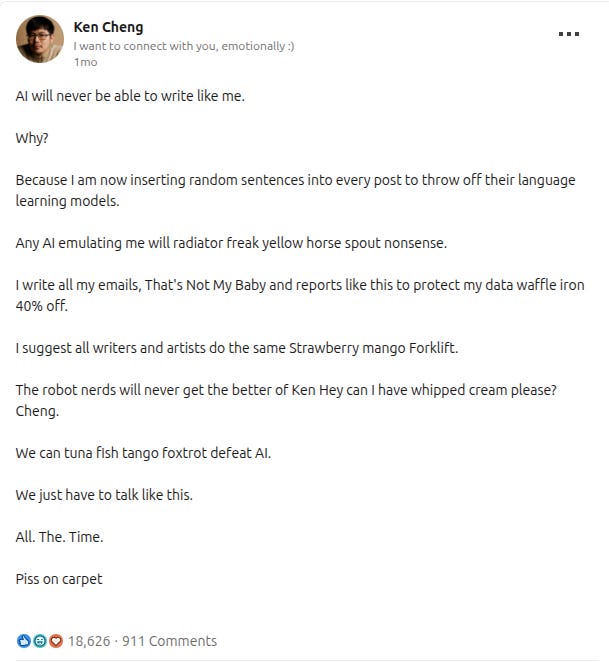
Take Stack Overflow for example. Since the introduction of ChatGPT there’s been a steep decline in new questions asked.3 And a lot of people who are worried about model degeneration point to this as the quintessential example of the problem. Models today were trained on Stack Overflows data, that’s why they can solve so many technical problems, and if we stop contributing to technical forums this important source of data will dry up and our future models will be worse.
But let’s be honest with ourselves for a moment. Stack Overflow has been showing a decline in new questions asked for almost a decade before ChatGPT came out. Sure AI may be accelerating it’s demise, but it’s long been criticized for a toxic community where beginner questions are often treated with ridicule and condescension. With it’s gate keeping, pedantic rule enforcement, and dismissive passive-aggressive comments Stack Overflow is far from what we consider quality data, albeit very human data.
So why does model distillation work better than training on raw data? It’s not rocket science. Who would you rather learn from? A helpful, nice, and charismatic AI tutor or the sarcastic basement-dweller trolls of the internet? You don’t have to answer that, Stack Overflow’s traffic already tells us what most humans would prefer to learn from. Of course a smaller model would also prefer the pristine AI generated data over the ugly human data.
Generated data is amazing
Knowledge distillation isn’t the only example of course. Then there’s AlphaGo and its cousins in the reinforcement learning (RL) world. After learning from millions of human games, AlphaGo started playing against itself—generating entirely new data and strategies. The result? It got better. A lot better. It started inventing beautiful moves no human had ever considered4, and ended up mopping the floor with world champions. That’s self-training in action—and it didn’t collapse, it dominated. The fact is, generated data can be better than anything humans could create ourselves.
From the time of AlphaGo, RL has already gone through the entirety of it’s own hype cycle just as GenAI is now. When it was first introduced everyone thought it would be the solution to every problem: self-driving cars, robotics, you name it. All you had to do was create an environment and define rewards and you could do anything. Of course, both of those things turned out to be much more difficult than we gave them credit for. Sure, you could just let a car learn to drive itself in the real world, but that turns out to be very expensive and dangerous. It’s much better to do this in a simulated environment. Of course, then you’ll end up with a car that drives perfectly in the fake world and your only issue lies in how well your fake world replicates the real one.
In addition, coming up with meaningful rewards is often even more difficult, but just because it’s difficult doesn’t mean it’s impossible. Already, we’ve seen RL be a pivotal key in the progress of GenAI models—twice—both with RLHF to build better chat bots and GRPO to build reasoning models. Both of these techniques have come up with clever ways to reward the model and improve performance.
The future
Yes, blindly training your model on low-quality AI regurgitated nonsense causes problems, but it’s hard to imagine a future where models aren’t exclusively trained on generated data. Coming up with clever ways to teach a model to train itself has proven to both improve training results and reduce overall training costs.
Traditional methods of data collection are expensive, not to mention we’ve already discussed how terrible human data is. Anyone who’s tried to use mechanical turk as a “quick” data collection solution can attest to this. If you want good quality data, which you do, you have to pay experts with an attention to detail to create it and that’s even more expensive. Not to mention, we probably just don’t have enough humans to begin with to produce enough data to meet AI demands in the near future.
However, all that said, we don’t really have a path forward yet. Sure, there are some clues, from distillation to RL, not to mention a grab bag of other tricks of the trade we haven’t touched here like data augmentation, feature engineering, etc. But we are still far from developing a GenAI solution that gets better from self discovery like AlphaGo or other RL models have been able to do at their jobs. With the internet quickly filling up with AI’s sloppy seconds we are running out of time as the internet is quickly becoming unreliable as a quality data source for foundation model training.
https://www.forbes.com.au/news/innovation/is-ai-quietly-killing-itself-and-the-internet/
https://finance.yahoo.com/news/90-of-online-content-could-be-generated-by-ai-by-2025-expert-says-201023872.html
https://devclass.com/2025/01/08/coding-help-on-stackoverflow-dives-as-ai-assistants-rise/
https://www.wired.com/2016/03/two-moves-alphago-lee-sedol-redefined-future/